On-premise установка отказоустойчивой версии Cloudmaster⚓︎
По итогам on-premise установки отказоустойчивой версии Cloudmaster её модули (приложения) будут расположены в 3 ВМ следующим образом:
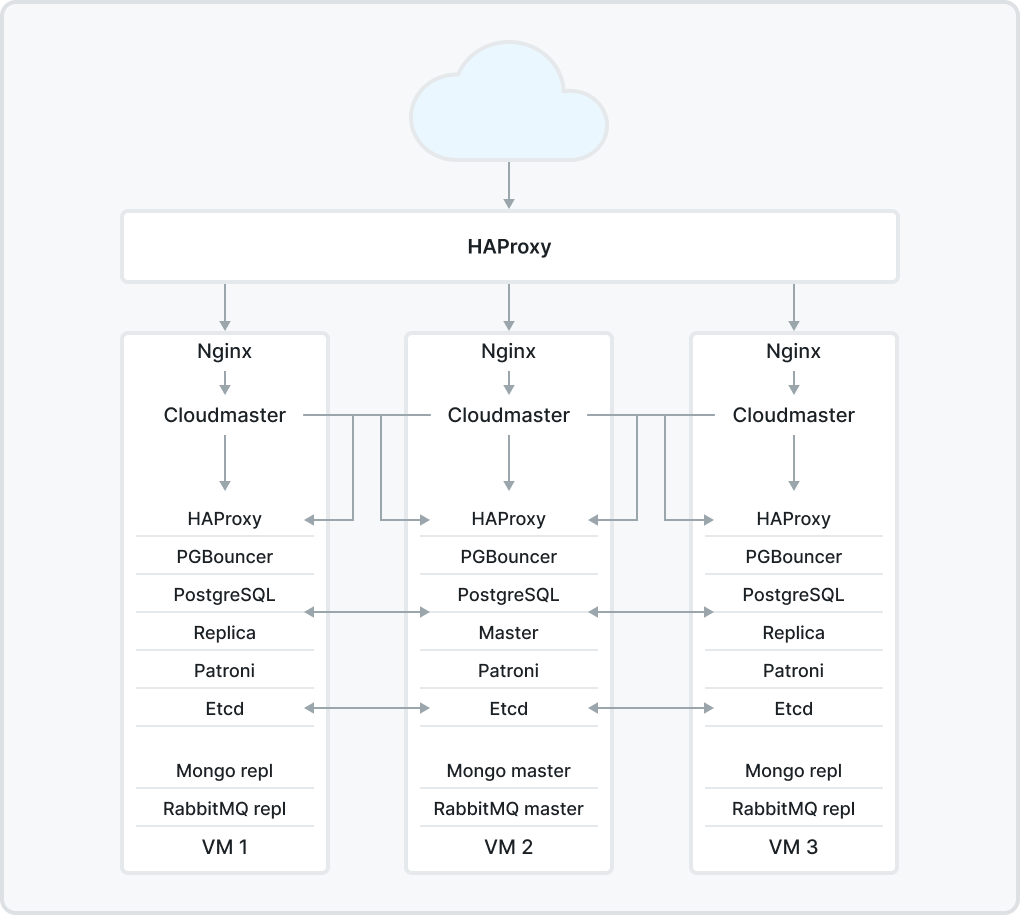
где
Компоненты высокой доступности
Patroni используется для автоматизации управления экземплярами PostgreSQL и автоматического переключения при сбое,
etcd ― распределенное надежное хранилище "ключ-значение" для наиболее важных данных распределенной системы. etcd написан на Go и использует алгоритм консенсуса Raft для управления реплицируемым журналом высокой доступности. Он используется Patroni для хранения информации о состоянии кластера и параметрах конфигурации PostgreSQL.
Компоненты балансировки нагрузки
HAProxy ― бесплатное, очень быстрое и надежное решение, обеспечивающее высокую доступность, балансировку нагрузки и проксирование для приложений на основе TCP и HTTP,
PgBouncer ― пул соединений для PostgreSQL.
Подготовительные работы⚓︎
Предварительные требования
Для on-premise установки отказоустойчивой версии Cloudmaster вам понадобятся:
-
3
ВМдля самого кластера, -
как минимум одна
ВМдля балансировщика входящего HTTP-трафика, -
все
ВМдолжны иметь сетевую связанность. Задержка сети междуВМне должна превышать 5 мс.
| Параметры каждой ВМ кластера | Параметры ВМ балансировщика входящего HTTP-трафика |
|---|---|
| ОС Ubuntu 20.04 LTS 8 CPU 32GB RAM 100GB SSD 1Gbit сетевой интерфейс |
ОС Ubuntu 20.04 LTS 4 CPU 8GB RAM 20GB SSD 1Gbit сетевой интерфейс |
Допустим, ВМ имеют такие IPv4-адреса и имена:
-
3
ВМкластера ― node1 10.0.0.4, node2 10.0.0.5, node3 10.0.0.6, -
ВМбалансировщика ― lb1 10.0.0.7 ― внутренний интерфейс, cluster.ваш_домен.ru ВНЕШНИЙ_IP ― внешний интерфейс.
Чтобы ВМ видели во внутренней сети друг друга по именам, настройте дополнительно DNS-сервер и используйте его либо на каждой ВМ в файл /etc/hosts (sudo nano /etc/hosts) добавьте:
| ВМ | /etc/hosts |
|---|---|
| ВМ кластера node1 | 10.0.0.5 node2 10.0.0.6 node3 10.0.0.7 lb1 |
| ВМ кластера node2 | 10.0.0.4 node1 10.0.0.6 node3 10.0.0.7 lb1 |
| ВМ кластера node3 | 10.0.0.4 node1 10.0.0.5 node2 10.0.0.7 lb1 |
| ВМ балансировщика lb1 | 10.0.0.4 node1 10.0.0.5 node2 10.0.0.6 node3 |
На внешнем DNS-сервере пропишите A-запись на имя cluster.ваш_домен.ru и ВНЕШНИЙ_IP ВМ балансировщика.
Установка Cloudmaster⚓︎
На всех 3 ВМ кластера установите Cloudmaster, следуя инструкции до момента, когда терминал отобразит следующее сообщение:
Дождитесь завершения установки основного модуля Cloudmaster и приватных агентов (после завершения всех процессов терминал покажет 100%-ную загрузку).
При установке Cloudmaster в параметре server FDQN укажите
-
внешний IP-адрес или
-
если есть и вы его знаете, доменное имя
ВМбалансировщика.
После установки остановите все сервисы Cloudmaster внутри всех ВМ кластера следующей командой:
Настройка балансировщика⚓︎
На ВМ балансировщика нужно установить HAProxy .
sudo apt install --no-install-recommends software-properties-common
sudo add-apt-repository ppa:vbernat/haproxy-2.8 -y
sudo apt install haproxy=2.8.\*
В файле конфигурации HAProxy (sudo nano /etc/haproxy/haproxy.cfg) найдите и закомментируйте команду option httplog.
У вас должны появиться следующие записи:
В конец файла конфигурации HAProxy (sudo nano /etc/haproxy/haproxy.cfg) добавьте следующее:
frontend https-in
mode tcp
bind *:443
default_backend https-servers
backend https-servers
mode tcp
balance roundrobin
server node1 10.0.0.4:443 send-proxy
server node2 10.0.0.5:443 send-proxy
server node3 10.0.0.6:443 send-proxy
listen rabbitmq
bind *:5672
mode tcp
balance roundrobin
timeout client 3h
timeout server 3h
option clitcpka
server node1 node1:5672 check inter 5s rise 2 fall 3 init-addr none
server node2 node2:5672 check inter 5s rise 2 fall 3 init-addr none
server node3 node3:5672 check inter 5s rise 2 fall 3 init-addr none
После изменения конфигурационного файла перезапустите сервис HAProxy следующей командой:
Настройка Nginx на всех трёх ВМ кластера⚓︎
На всех 3 ВМ кластера измените конфигурацию Nginx (sudo nano /opt/cloudmaster/nginx/cloudmaster.conf).
Измените строку listen 443 на строку:
Затем добавьте после нее следующие 2 строки:
После изменения конфигурационного файла перезапустите сервис Nginx следующей командой:
Настройка RabbitMQ на всех трёх ВМ кластера⚓︎
На всех 3 ВМ кластера измените файл конфигурации RabbitMQ (sudo nano /etc/rabbitmq/rabbitmq-env.conf).
Закомментируйте строку NODE_IP_ADDRESS=127.0.0.1, чтобы её итоговое содержание было таким:
После изменения конфигурационного файла перезапустите сервис RabbitMQ следующей командой:
Скопируйте параметры на node1.
Последовательность настройки модуля на нодах
Настройте модуль RabbitMQ на нодах в следующем порядке: скопируйте нижеуказанные параметры на node1, затем подставьте их в node2 и node3.
Откройте на node1 файл .erlang.cookie:
Скопируйте его содержимое на две оставшиеся ВМ (node2 и node3) по такому же пути:
Скопируйте пароль на **node1** (параметр **rabbit.password**) из файла **/opt/cloudmaster/services/integration/application.properties** и запомните его для последующего указания в командах `ВМ` на **node2** и **node3**.
На node2 и node3 выполните следующие команды:
sudo systemctl restart rabbitmq-server
sudo rabbitmqctl stop_app
sudo rabbitmqctl reset
sudo rabbitmqctl join_cluster rabbit@node1
sudo rabbitmqctl start_app
sudo rabbitmqctl set_policy --vhost local_vhost ha-all "." '{"ha-mode":"all"}'
sudo rabbitmq-plugins enable rabbitmq_management
sudo rabbitmqctl change_password cloudmaster ПАРОЛЬ_КОТОРЫЙ_ВЗЯЛИ_НА_NODE1
На всех 3 ВМ кластера в файле /opt/cloudmaster/services/integration/application.properties измените параметры подключения модуля cm-integration на
Затем в файле /opt/cloudmaster/services/agent-private/ application.properties измените параметры подключения универсального приватного агента на
Настройка Mongo DB⚓︎
Измените на всех 3 ВМ кластера конфигурационный файл /etc/mongod.conf (sudo nano /etc/mongod.conf).
На node1:
На node2:
На node3:
После изменения конфигурационных файлов перезапустите сервис MongoDB на каждой ВМ кластера следующей командой:
Далее на node1 запустите консоль MongoDB командой:
В консоли выполните mongo-команды:
rs.initiate( {
_id : "rs0",
members: [
{ _id: 0, host: "node1" },
{ _id: 1, host: "node2" },
{ _id: 2, host: "node3" }
]
})
Выйдите из консоли MongoDB.
Далее на всех 3 ВМ кластера измените файл конфигурации Универсального приватного агента (/opt/cloudmaster/services/agent-private/application.properties).
Теперь у него такая строка подключения:
mongo.db.private.agent.uri=mongodb://10.0.0.4,10.0.0.5,10.0.0.6/cloudmaster-agent-private?directConnection=false
Настройка PostgreSQL⚓︎
На всех ВМ кластера остановите все сервисы Cloudmaster
На node2 и node3 остановите PostgreSQL и удалите базы:
Далее выполните все команды на ВМ балансировщика (так же можно создать и использовать ещё одну ВМ с Ubuntu 20.04).
Установите Ansible:
Внимание!
Вам потребуется система Ansible версии 2.11.0. Возможно для её установки потребуется подключить и использовать отдельный специальный репозиторий.
Подробнее см. документацию Ansible.
Добавьте установку зависимостей на нодах node1, node2, node3 кластера.
Клонируйте репозиторий:
Перейдите в новую папку:
Установите зависимости для Ansible:
ansible-galaxy collection install community.general
ansible-galaxy collection install ansible.posix
ansible-galaxy collection install ansible.windows
ansible-galaxy collection install community.postgresql
Внесите нужные изменения в конфигурационный файл inventory (sudo nano inventory):
[etcd_cluster]
10.0.0.4
10.0.0.5
10.0.0.6
[balancers]
10.0.0.4
10.0.0.5
10.0.0.6
# PostgreSQL nodes
[master]
10.0.0.4 postgresql_exists=true
[replica]
10.0.0.5
10.0.0.6
# Connection settings
[all:vars]
ansible_python_interpreter='/usr/bin/env python3'
ansible_connection='ssh'
ansible_ssh_port='22' #ssh порт, по которому Ansible идет на ВМ кластера
ansible_user='ubuntu' #sudo пользователь на ВМ кластера, под которым Ansible будет выполнять свои скрипты
#далее или пароль
ansible_ssh_pass='пароль_пользователя' # если доступ по паролю а не по ключу, то нужно установить пакет sshpass командой sudo apt install sshpass
#или ключ - выбрать один из двух вариантов
ansible_ssh_private_key_file=путь_до_приватного_ssh_ключа для доступа по ssh на ВМ кластера
[pgbackrest:vars]
ansible_user='postgres'
ansible_ssh_pass='ПАРОЛЬ_ПОСЛОЖНЕЕ_И_ПОДЛИННЕЕ'
Проверьте доступность ВМ кластера с помощью команды:
В ответ вы получите подобный ответ:
10.0.0.4 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python3"
},
"changed": false,
"ping": "pong"
}
10.0.0.6 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python3"
},
"changed": false,
"ping": "pong"
}
10.0.0.5 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python3"
},
"changed": false,
"ping": "pong"
}
Если вы не получили подобный ответ, Ansible не может попасть на ВМ кластера и нужно правильно заполнить параметры в файле inventory, перечисленные выше.
Далее внесите изменения в файл vars/main.yml (sudo nano vars/main.yml):
vip_interface: "eth0" # имя интерфейса на ВМ кластера. Можно посмотреть командой ip a
patroni_cluster_name: "ha-cluster"
patroni_install_version: "3.0.2"
patroni_superuser_username: "postgres"
patroni_superuser_password: "пароль_посложнее_и_подлиннее" patroni_replication_username: "replicator"
patroni_replication_password: "пароль_посложнее_и_подлиннее"
synchronous_mode: false
with_haproxy_load_balancing: true
postgresql_version: "14"
pgbouncer_pools:
- { name: "postgres", dbname: "postgres", pool_parameters: "" }
- { name: "cm-analytics", dbname: "cm-analytics", pool_parameters: "pool_size=200 pool_mode=session" }
Остальные параметры оставьте без изменений.
Запустите установку PostgreSQL кластера следующей командой:
Если пользователь, под которым Ansible будет применять изменения конфигурации на ВМ, использует для входа на ВМ логин и пароль, а не ключ, и если пользователю для выполнения sudo требуется вводить пароль, то команду следует выполнять с ключом "--ask-become-pass":
Если всё установилось без ошибок, проверьте статус кластера. Для этого выполните команду на любой ВМ кластера:
Вывод должен быть примерно такой:
+ Cluster: ha-cluster --------+---------+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+--------+----------+---------+---------+----+-----------+
| node1 | 10.0.0.4 | Leader | running | 7 | |
| node2 | 10.0.0.5 | Replica | running | 7 | 0 |
| node3 | 10.0.0.6 | Replica | running | 7 | 0 |
+--------+----------+---------+---------+----+-----------+
На всех ВМ кластера измените параметр подключения spring.datasource.jdbcurl сервисов к базе данных в файлах:
-
/opt/cloudmaster/services/auth/application.properties
-
/opt/cloudmaster/services/integration/application.properties
-
/opt/cloudmaster/services/main/application.properties
-
/opt/cloudmaster/services/notifications/application.properties
-
/opt/cloudmaster/services/reports/application.properties
-
/opt/cloudmaster/services/settings/application.properties
на такой:
На 2й и 3й ВМ кластера измените параметр spring.datasource.password на значение, взятое из этого параметра на 1й ВМ.
После изменения параметров подключения к базе на каждой ВМ перезапустите все сервисы Cloudmaster:
for service in $(sudo systemctl list-units {}all -full --no-legend "cloudmaster-*.service" | awk '{print $1}'); do
sudo systemctl restart $service
echo "Перезапущен сервис $service"
sleep 30
done
Настройка оркестрации Универсального приватного агента⚓︎
На всех ВМ кластера выполните:
curl https://io.cloudmaster.ru/master_selector.sh > /opt/cloudmaster/util/master_selector.sh
chmod +x /opt/cloudmaster/util/master_selector.sh
Добавьте в cron новую задачу:
с такой строкой:
Настройка ссылок на Cloudmaster в почтовых уведомлениях⚓︎
Чтобы в e-mail письмах, в ссылках был записан IP-адрес или доменное имя балансировщика HA-кластера, необходимо на текущей мастер-ноде (Leader) кластера выполнить команду:
wget -O /opt/cloudmaster/util/setup_ha-entrance4mail.sh https://io.cloudmaster.ru/ha-cluster/setup_ha-entrance4mail.sh && chmod +x /opt/cloudmaster/util/setup_ha-entrance4mail.sh && /opt/cloudmaster/util/setup_ha-entrance4mail.sh
Эта команда:
-
скачает и запишет в /opt/cloudmaster/util/ новую утилиту setup_ha-entrance4mail.sh,
-
сделает её (утилиту) исполняемой и
-
сразу запустит.
Когда утилита запустится, необходимо ввести IP-адрес или доменное имя, которое назначили для HA-proxy.
Пример:
# wget -O /opt/cloudmaster/util/setup_ha-entrance4mail.sh https://io.cloudmaster.ru/ha-cluster/setup_ha-entrance4mail.sh && chmod +x /opt/cloudmaster/util/setup_ha-entrance4mail.sh && /opt/cloudmaster/util/setup_ha-entrance4mail.sh
--2024-08-22 09:23:51-- https://io.cloudmaster.ru/ha-cluster/setup_ha-entrance4mail.sh
Resolving io.cloudmaster.ru (io.cloudmaster.ru)... 213.180.193.247, 2a02:6b8::1da
Connecting to io.cloudmaster.ru (io.cloudmaster.ru)|213.180.193.247|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 577 [text/x-sh]
Saving to: ‘/opt/cloudmaster/util/setup_ha-entrance4mail.sh’
/opt/cloudmaster/util/setup_ha-entrance4mail.sh 100%[=========================================================================================================================================>] 577 --.-KB/s in 0s
2024-08-22 09:23:51 (79.7 MB/s) - ‘/opt/cloudmaster/util/setup_ha-entrance4mail.sh’ saved [577/577]
Введите домен или IP входного балансировщика запросов кластера CloudMaster: 10.10.15.77
Адрес входа для email-уведомлений изменён на '10.10.15.77'
Обновление отказоустойчивой версии⚓︎
Рекомендации по обновлению
Рекомендуем отключить обычное системное обновление пакета, т.к. для обновления кластерной версии требуется использовать наш специальный скрипт обновления.
Для отключения незапланированного обновления пакета Cloudmaster введите на всех нодах кластера следующую команду:
Обновление версии Cloudmaster в варианте отказоустойчивой установки выполняется на каждой ноде кластера.
Для этого выполните 3 шага:
-
Определите, какая нода кластера является лидером. Для этого на любой ноде кластера выполните команду:
Вывод должен быть примерно такой:
+ Cluster: ha-cluster --------+---------+----+-----------+ | Member | Host | Role | State | TL | Lag in MB | +--------+----------+---------+---------+----+-----------+ | node1 | 10.0.0.4 | Leader | running | 7 | | | node2 | 10.0.0.5 | Replica | running | 7 | 0 | | node3 | 10.0.0.6 | Replica | running | 7 | 0 | +--------+----------+---------+---------+----+-----------+В поле Host вы увидите IP-адрес необходимой ноды.
-
Зайдите по SSH на ноду с ролью Leader, IP-адрес которой вы узнали на первом шаге.
Скачайте специальный BASH-скрипт обновления и выполните его:
wget -O cloudmaster_cluster_upgrade.sh https://io.cloudmaster.ru/cloudmaster_cluster_upgrade.sh && chmod +x cloudmaster_cluster_upgrade.sh && ./cloudmaster_cluster_upgrade.shВ случае успешного выполнения на экран будет выведено сообщение:
Обновление Cloudmaster успешно завершено ! Не забудьте повторить процедуру на остальных нодах кластера !
-
Повторите скачивание и выполнение специального скрипта обновления на остальных нодах кластера.